A previsão de demanda trata-se do processo de antecipar o nível da procura por um determinado produto ou serviço de uma empresa. Então, para estudarmos esse tópico, utilizamos um banco de dados sobre vendas de alguns produtos que, por questões de privacidade, foi mascarado por frutas.
Além do domínio das técnicas de modelagem, é de suma importância a compreensão dos fatores que influenciam a receita da venda desses produtos. Assim, a partir de uma visão holística, podemos determinar as features do modelo.
Começamos com as variáveis macroeconômicas como a taxa básica de juros - a SELIC. A baixa desta taxa influencia a renda per capta e consequentemente o consumo, resultando em maior demanda dos produtos que estamos estudando. Outro fator que potencialmente pode ser incluído no modelo é a densidade populacional.
É intuitivo pensar que a demanda está diretamente relacionada a este fator, no entanto depende também do perfil demográfico. Percebemos que alguns fatores como o gênero, a idade e a renda determinam se o perfil estará predisposto a consumir um determinado produto em detrimento de outros.
Nos tópicos seguintes faremos uma contextualização do problema a ser modelado, onde englobaremos uma análise em cima do banco de dados e as modificações feitas nesse conjunto. Logo após, falaremos sobre o método utilizado na previsão da demanda e faremos uma breve análise dos resultados obtidos.
Contextualização do Problema
Podemos visualizar na tabela abaixo, uma amostra do conjunto de dados,
| Ano | Semana | Canal Comercial | UF | Código IBGE | Município | Produto | Valor | Volume |
|---|---|---|---|---|---|---|---|---|
| 2017 | 1 | AZUL | BA | 2900702 | Alagoinhas | Maçã | 20.561924 | 1.125896 |
| 2017 | 1 | AZUL | BA | 2901106 | Amélia Rodrigues | Maçã | 14.527124 | 0.716479 |
| 2017 | 1 | AZUL | BA | 2901700 | Antônio Cardoso | Maçã | 36.827021 | 2.047083 |
| 2017 | 1 | AZUL | BA | 2902609 | Baixa Grande | Maçã | 32.530194 | 1.842375 |
| 2017 | 1 | AZUL | BA | 2905701 | Camaçari | Maçã | 60.866940 | 3.377687 |
Neste conjunto há mais de 4 milhões de linhas, e contém:
- 2 canais comerciais: azul e verde
- Mais de 4500 municípios
- 14 produtos
- As semanas de 2017, 2018 e 2019
O que queremos prever são os Valores e os Volumes de cada semana de 2019 com base nas semanas de 2017 e 2018.
Análise dos dados
Visualizando o comportamento do volume de cada produto,
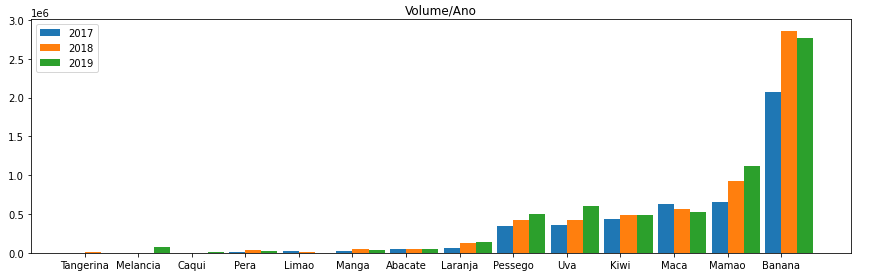
podemos perceber que a quantidade de cada produto é bem variada, e que a Tangerina, Melancia e o Caqui não aparecem em todos os anos.
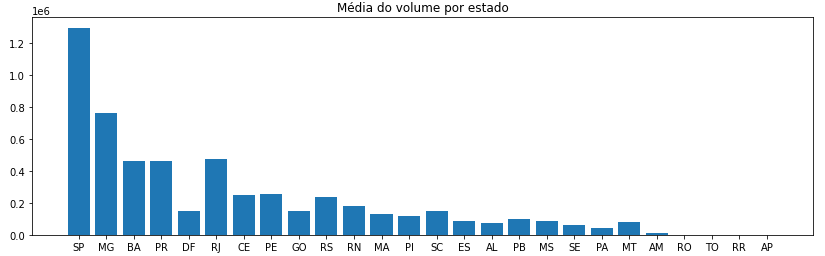
A imagem abaixo representa a média do volume total por estado, é possível notar que o estado de SP e MG, possuem a maior demanda de produtos.
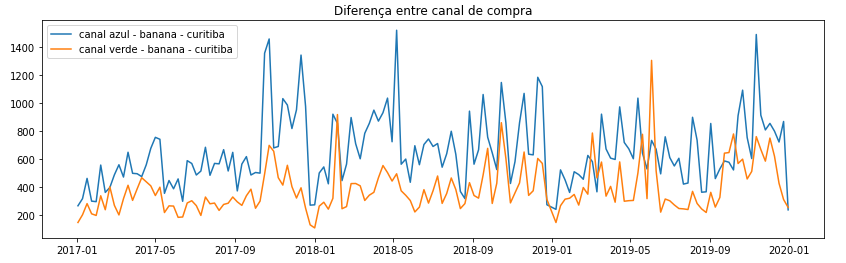
Analisando a cidade de Curitiba com o produto Banana, percebemos que há uma diferença significativa entre os dois canais de compra. Não apenas pelo volume, mas também o comportamento de cada canal é diferente, e esse padrão se repete nos demais municípios.
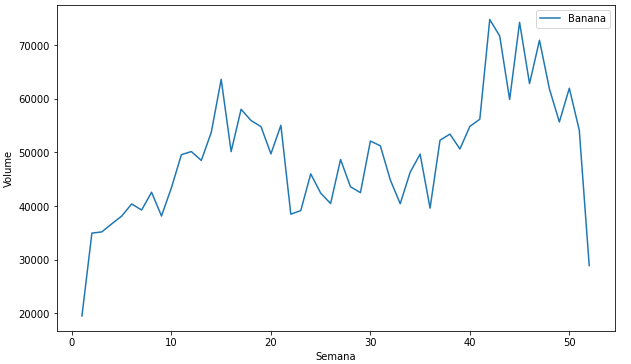
Olhando agora para os produtos, ao analisarmos o seu comportamento verificamos que os produtos também tem características diferentes, como podemos visualizar nas imagens abaixo.
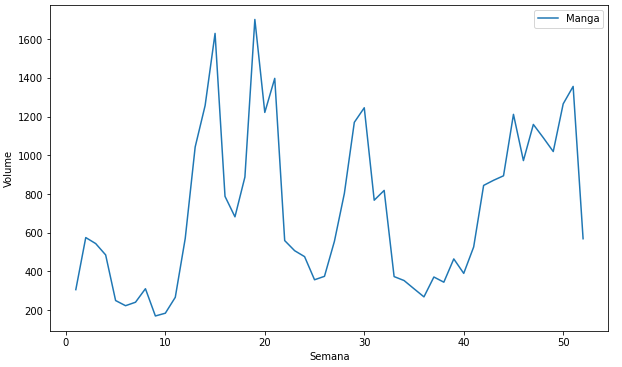
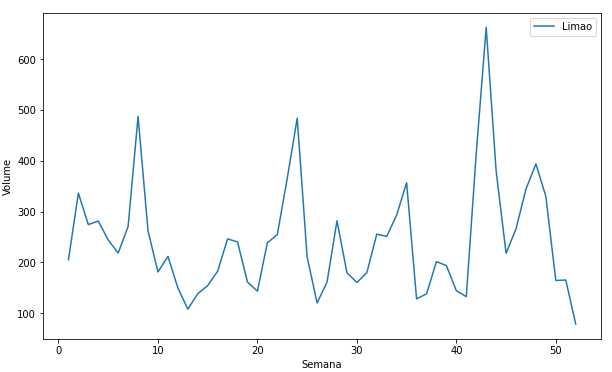
Modificações
A fim de obtermos uma melhor modelagem, retiramos as três frutas - Tangerina, Melancia e Caqui - que não apareciam nos três anos. Além da retirada de alguns municípios que não apareciam mais de 52 vezes, também removemos a previsão de Valor, uma vez que os dois possíveis targets - Valor e Volume - possuem alta correlação.
Por outro lado, para cada observação, que corresponde a uma semana, adicionamos
- A população correspondente a cada município;
- Se houve greve naquela semana;
- Se é período festivo ou não;
- Uma numeração para cada semana, pela ordem do volume média de 2017 e 2019.
Sabe-se que períodos festivos podem impulsionar a demanda nesses intervalos. Adicionamos essa variável com alguns feriados, os quais são: o dia das mães, o dia dos namorados, a Black Friday e o natal. Não colocamos todos os feriados nacionais pois observamos que apenas os feriados mencionados apresentaram um aumento significativo no Volume dos produtos. Também refletimos que as semanas que possuem maiores volumes devem possuir um maior foco, visto que são esses períodos que deveríamos prever a possível subida nas vendas, sendo eles feriados ou não.
Por outro lado, greves - como a greve dos caminhoneiros de maio à junho de 2018, bem como fenômenos que interrompam a cadeia de suprimentos - podem influenciar a oferta dos produtos e, assim, dimininundo a demanda destes itens.
Infelizmente não conseguimos adicionar a taxa Selic ou o IDH de cada município. Uma vez que o conjunto de dados é de apenas 3 anos, não visualizamos uma melhora no modelo ao adicionar estes dois fatores.
Principal abordagem do estudo
Entre as abordagens que utilizamos para resolver o problema de previsão de demanda, o Gradient Boosting com Janela Temporal e com Defasagem de uma semana foi o que obteve o melhor resultado.
Validação de Séries Temporais: Janela de Expansão
Para obter um melhor resultado em nosso modelo utilizamos um método de validação de séries temporais chamado janela temporal. Existem dois tipos, a janela deslizante, utilizada em séries temporais diárias e horárias, e a janela de expansão, que é usada com mais frequência em séries temporais semanais, mensais ou trimestrais. Devido a natureza dos nossos dados utilizaremos a janela de expansão. Para essa validação são requeridos quatro hiperparâmetros,
- Tamanho da janela inicial;
- Tamanho da janela final;
- Tamanho da janela de previsão;
- Incremento da expansão da janela. Abaixo temos um exemplo visual do método,
![Visualização do método Janela Expansiva. Imagem tirada de [4]](/img/previsao-de-demanda/janela-expansiva.png)
Podemos observar que nesse método, a cada passo utiliza mais dados que o anterior para o treino do modelo, enquanto que o intervalo de predição é fixo.
Defasagem
Para adicionar o efeito temporal em nosso modelo de Gradient Boosting adicionamos em nosso conjunto de dados uma defasagem semanal. Por exemplo, quando olhamos para uma determinada semana estaremos olhando também para a os dados da semana anterior. Assim, para essa modificação utilizaremos a função shift. Abaixo temos um exemplo para a cidade de São Paulo, canal comercial azul com o produto banana.
| Volume | Ano | Semana | Peso Semana | Feriado | Greve | Volume1 | Ano1 | Semana1 | Peso Semana1 | Feriado1 | Greve1 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 445.957011 | 2017 | 1 | 1 | 0 | 0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 757.727738 | 2017 | 2 | 5 | 0 | 0 | 445.957011 | 2017 | 1 | 1 | 0 | 0 |
| 729.170931 | 2017 | 3 | 4 | 0 | 0 | 757.727738 | 2017 | 2 | 5 | 0 | 0 |
| 664.278403 | 2017 | 4 | 7 | 0 | 0 | 729.170931 | 2017 | 3 | 4 | 0 | 0 |
| 803.889458 | 2017 | 5 | 12 | 0 | 0 | 664.278403 | 2017 | 4 | 7 | 0 | 0 |
| … | … | … | … | … | … | … | … | … | … | … | … |
Onde Volume1, Ano1, Semana1, Peso Semana1, feriado1 e greve1, correspondem aos dados da semana anterior.
Gradient Boosting
É um modelo ensemble do pacote sklearn. Ele consiste basicamente em um modelo aditivo que utiliza aprendizes fracos, normalmente árvores de decisão, e uma função perda para ser otimizada a fim de construir um modelo forte. O método possui diversos parâmetros para serem otimizados, porém para esse problema aperfeiçoaremos os seguintes,
n_estimators: número de árvores;max_depth: número de nós de cada árvore;learning_rate: taxa de aprendizado;max_features: quantidade de features usada para fazer a divisão de cada nó da árvore.
Para fazer essa otimização utilizamos o Grid Search e obtivemos como resultados: max_depth=2, learning_rate=0.05, max_features=log2. Note que o n_estimator não está presente na lista anterior, isso porque vamos otimizá-lo para cada cidade, dentro do próprio algoritmo de previsão.
Resultado e Comparação
Para compararmos o método proposto utilizaremos o Gradient Boosting sem janela temporal e sem defasagem, onde apenas otimizamos seus parâmetros da mesma forma que foi feita com o modelo proposto. Os resultados para cada método podem ser observados na tabela a seguir.
| C.C. VERDE | GB | GB_Janela | C.C. AZUL | GB | GB_Janela |
|---|---|---|---|---|---|
| Abacate | 0.76 | 0.87 | Abacate | 0.6 | 0.72 |
| Banana | 0.91 | 0.95 | Banana | 0.84 | 0.90 |
| Kiwi | 0.71 | 0.88 | Kiwi | 0.48 | 0.59 |
| Laranja | 0.75 | 0.78 | Laranja | 0.62 | 0.74 |
| Limão | 0.04 | 0.71 | Limão | 0.1 | 0.73 |
| Maçã | 0.81 | 0.85 | Maçã | 0.35 | 0.76 |
| Mamão | 0.86 | 0.91 | Mamão | 0.55 | 0.64 |
| Manga | 0.47 | 0.63 | Manga | 0.06 | 0.08 |
| Pera | 0.57 | 0.67 | Pera | 0.26 | 0.33 |
| Pêssego | 0.89 | 0.92 | Pêssego | 0.48 | 0.51 |
| Uva | 0.62 | 0.70 | Uva | 0.42 | 0.47 |
Podemos destacar o Limão, que em ambos os canais comerciais obteve um aumento de aproximadamente 0.7 no R2. Um exemplo mais visual pode ser observado abaixo, previmos o Volume das semanas de 2019 do produto Abacate, no canal comercial Azul da cidade de Belo Horizonte. Sendo o gráfico azul o Volume real, e o gráfico laranja a previsão do Gradient Boosting sem janela temporal e sem defasagem.
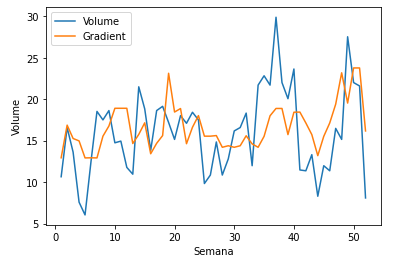
Da mesma maneira, o gráfico azul é o Volume real, enquanto que o gráfico laranja é o Gradient Boosting com janela temporal e com defasagem.
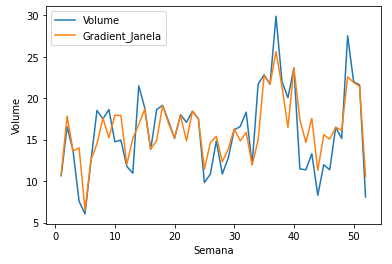
Além do visual,podemos verificamos que o R2 de cada método foi:
- Gradient Boosting sem janela temporal e sem defasagem: 0.13
- Gradient Boosting com janela temporal e com defasagem: 0.7
Pode-se notar que o Gradient Boosting com janela temporal e defasagem obteve uma melhora significativa com relação ao seu adversário.
Outras abordagens poderiam ter sido utilizadas para a modelagem do problema em questão, entretanto por questões de tempo não foram realizadas, são elas,
- Implementação de métodos de séries temporais que contemplem variáveis exógenas : VARMAX e Panel Regression;
- Redes neurais com arquitetura recorrente ou com memória (LSTM);
- Abordagem Híbrida de Séries Temporais + ANN.
Referências
- [1] BERGMEIR, C.; HYNDMAN, R.J.;KOO, B. - A Note on the Validity of Cross-Validation for Evaluating Time Series Prediction; Monash university, 2015.
- [2] KHANDELWAL, I.; ADHIKARI, R; VERMA, G. - “Time Series Forecasting using Hybrid ARIMA and ANN Models based on DWT Decomposition”, ICCC, 2015.
- [3] ZHANG, G. P. - “Time series forecasting using a hybrid ARIMA and neural network model”; Neurocomputing 50, p . 159 – 175, 2005.
- [4] BELL, F.; SMYL, S. - “Forecasting at Uber: An Introduction”. Disponível em: https://eng.uber.com/forecasting-introduction/