Este blogpost faz referência ao 3º desafio do curso de Machine Learning proposto dentro do grupo CiDAMO da UFPR aos seus mais novos membros e tem como objetivo descrever o processo de solução encontrada pela equipe no tema reconhecimento de caracteres matemáticos. A turma foi dividida em 5 equipes e cada uma escolheu o assunto que mais lhe interessava explorar.
Faz parte do escopo dessa postagem, também, citar os projetos anteriores que foram utilizadas como referências, os datasets empregados, as dificuldades encontradas, os resultados finais, além dos próximos passos e objetivos.
Contextualização
O crescimento exponencial de dados que vemos nos últimos anos levou ao desenvolvimento de ferramentas que tornam possível produzir, rápida e automaticamente, modelos capazes de analisar dados maiores e mais complexos, e entregar resultados mais rápidos e precisos, mesmo em grande escala. E ao construir modelos precisos, uma organização tem mais chances de identificar oportunidades lucrativas, ou de evitar riscos desconhecidos.
Com o advento do Deep Learning, que é um tipo de Machine Learning, conseguimos reproduzir o mecanismo de aprendizagem e reconhecimento de um neurônio humano em linhas de código.
Técnicas de deep learning têm melhorado significativamente a capacidade dos computadores de reconhecer, classificar, detectar e descrever algum tipo de informação. Dessa forma ele tem sido usado para classificação de imagens, reconhecimento de fala, detecção de objetos e descrição de conteúdo, por exemplo.
Primeira Abordagem
Inicialmente, o grupo recorreu a literatura e à internet para encontrar referências a cerca do tema. Um trabalho anterior do CiDAMO disponível no GitHub[1], dos alunos João Fassina, Egmara Antunes e Renan Domingues, realizava o reconhecimento de dígitos matemáticos (0 a 9). Foi o primeiro passo tomado pela nossa equipe, antes de estender a solução para os demais caracteres matemáticos.
Na sequência, outro estudo local guiou o trabalho do nosso grupo. O graduando em Matemática, Carlos Henrique Venturi Ronchi, orientado pelo Prof. Abel Siqueira, coordenador do CiDAMO, realizou um estudo matemático a respeito do reconhecimento de caracteres[2], o que forneceu ainda mais insumos para a solução do problema. Por fim, usamos um curso de Machine Learning e Deep Learning no TensorFlow para nos auxiliar na montagem do nosso modelo.
Estudando o problema, identificamos que a solução para este seria um modelo de classificação de classes. Em uma primeira análise, consideramos 4 modelos de classificação diferentes para utilizar no nosso problema. Entre eles, estão: Artifitial Neural Networks (ANN), Random Forest, Support Vector Classification (SCV) e Convolutional Neural Networks (CNN). Após testar um primeiro modelo montado por nós e levando em consideração alguns pontos do trabalho anterior do CiDAMO, decidimos escolher o modelo de Redes Neurais Convolucionais (CNN) para dar continuidade no nosso trabalho, pois este modelo mostrou uma performance melhor, com maior acurácia, se comparado com os outros modelos.
Redes Neurais Convolucionais (CNN)
As redes neurais convolucionais foram desenvolvidas tomando como base o córtex visual de animais. Nela, assim como no córtex, temos várias regiões denominadas de campos receptivos e são formadas por subconjuntos selecionados do vetor de características a ser analisado. A estrutura das redes concolucionais possui 3 objetivos principais: Extração de características, mapeamento de características e subamostragem. A figura abaixo exemplifica o processo de uma rede convolucional.
![Ilustração do processo de uma rede convolucional. Fonte: Wikipedia [3]](https://upload.wikimedia.org/wikipedia/commons/6/63/Typical_cnn.png)
Cada campo receptível, na camada de convolução[4], é responsável por extrair características (features) locais da imagem. A extração dessas características locais faz com que a posição exata de cada característica seja irrelevante, desde que sua posição em relação às características vizinhas seja mantida. Por exemplo, no reconhecimento facial, não importa onde os olhos estejam posicionados, desde que eles estejam próximos e na posição correta em relação à orelha, nariz e boca. Desta forma, podemos analisar a imagem localmente e não globalmente, sendo possível descartar ruídos que estejam em volta do rosto.
Seguindo, cada camada computacional da rede é composta por diversos mapas de características (feature maps), que são regiões onde os neurônios compartilham os mesmos pesos sinápticos (kernels), que dão robustez ao modelo, fazendo com que ele seja capaz de lidar com variações de rotação, translação e distorção da imagem, reduzindo drasticamente o número de parâmetros a serem otimizados.
Após cada camada de convolução, são coletadas amostras de cada mapa de característica e reunidas em subamostragens (subsampling ou pooling). Uma camada de pooling[5] recebe cada saída do mapa de características da camada convolucional e prepara um mapa de características condensadas. O processo de max-pooling[6] é uma forma de a rede encontrar um determinado recurso em qualquer lugar de uma região da imagem. Em seguida, elimina a informação posicional exata, importando somente sua localização aproximada em relação a outros recursos. O processo é repetido pelo número de camadas escolhidas para o modelo.
Feito isso, é empregado o processo de flatenning[7], que basicamente pega as camadas de pooling da última subamostragem e as transforma em um único longo vetor que será usado como input para a rede neural artificial.
![Ilustração do processo de Flattening. Fonte: Super Data Science [7]](https://i.postimg.cc/cHqvbHxg/2-flatenning.png)
Por fim, nosso vetor pode ser usado na rede neural artificial[8]. O objetivo dessa rede é combinar exaustivamente as características em uma variedade de atributos para tornar a rede convolucional mais capaz de classificar as imagens.
A rede neural artificial então faz sua previsão da classe baseando-se nos dados do vetor e os pesos sinápticos. A classe que apresentar as maiores probabilidades de possuir as características do nosso vetor, mantendo também a posição relativa entre as características, será a escolhida pelo modelo. Abaixo temos um exemplo de rede neural para exemplificar.
![Exemplo de uma Rede Neural Artificial usada para estimar as probabilidades de cada classe. Fonte: TEXample [9]](../img/reconhecimento-caracteres/neural-network.png)
Obtenção do Banco de Dados
Para rodar nosso modelo, encontramos 3 datasets diferentes que poderiam ser usados na solução do problema. O dataset “Hand written math symbols”[10] é composto de mais de 100.000 imagens de caracteres matemáticos manuscritos de 45x45 pixels. Além dele, achamos o dataset “HASYv2”[11] que consiste em 150.000 símbolos manuscritos, divididos em 369 classes e disponibilizados em imagens de 32x32 pixels. Por fim, encontramos o dataset “Chars74k”[12] que consiste de 74.000 imagens de símbolos matemáticos, com 128x128 pixels de dimensão, tanto manuscritas, quanto segmentadas de cenários naturais e escritas a partir de fontes do computador. Tivemos alguns problemas antes de trabalhar com o dataset, como é de se esperar para um projeto de Machine Learning, pois haviam diversas imagens borradas, erradas ou até mesmo inapropriadas. Abaixo podemos ver alguns dos exemplos da pasta do símbolo “não existe” de imagens que tiveram que ser descartadas; na segunda imagem, o símbolo em si não está errado (existe unicamente), porém estava tabelado de maneira errada.
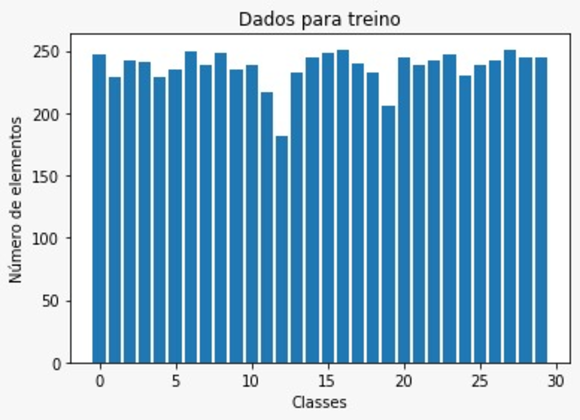
Após um extensivo trabalho de seleção, reunimos um conjunto de dados com caracteres manuscritos condizentes com a realidade. Após um estudo sobre o tamanho da amostra necessário para não afetar a acurácia do modelo, chegamos ao valor aproximado de 250 imagens para cada classe selecionada, nos deixando com um conjunto de 30 classes e perto de 7.000 imagens de 28x28 pixels. Abaixo podemos ver uma ilustração da quantidade de imagens para cada classe selecionada.
Modelo
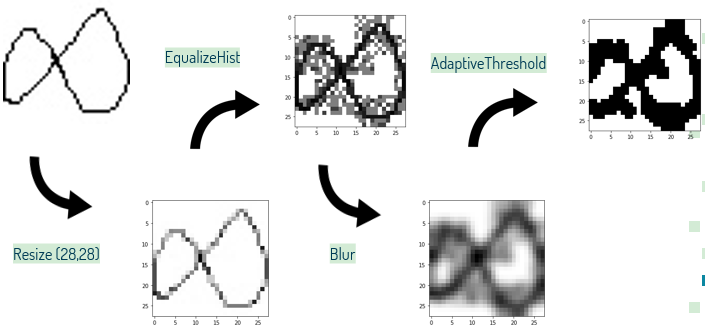
Antes de passar pela rede convolucional, as imagens precisam passar por algumas fases de processamento, sendo utilizada a biblioteca open source OpenCV[13] de visão computacional e aprendizade de máquinas. Primeiramente, a imagem é redimensionada (Resize) para 28x28 pixels, seguida de uma equalização do histograma (EqualizeHist) na imagem para acentuar detalhes perdidos no redimensionamento. Após, a imagem passa por um processo de suavização das linhas (Blur) para finalmente acertar a cor dos pixels estipulando um limite de intensidade no pixel para classificá-lo binariamente como branco ou preto (AdaptiveThreshold).
Abaixo temos uma ilustração do processo descrito acima para cada dataset diferente (“Chars74k”, “Hand written math symbols”, “HASYv2”), ficando clara a diferença no resultado.
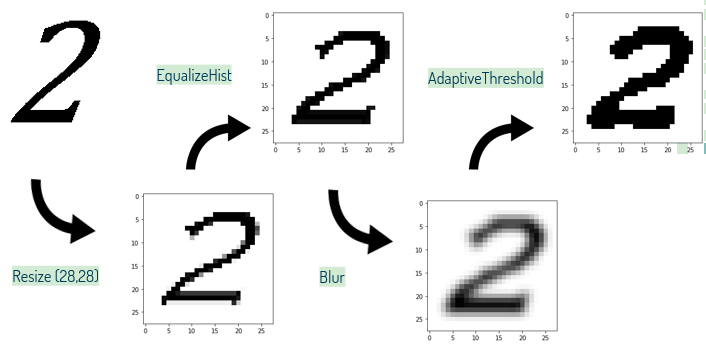
Para os símbolos manuscritos, a caligrafia pode influenciar bastante no aprendizado do modelo.
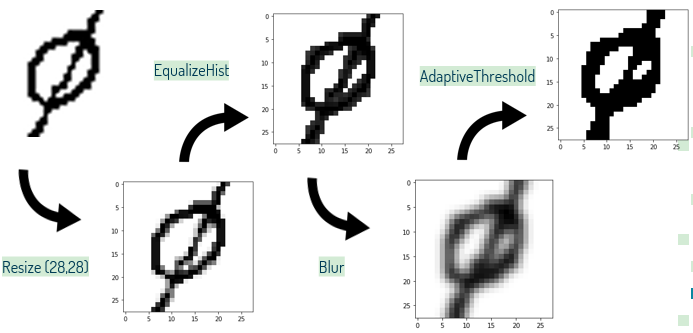
O resultado pode ser afetado por ruídos externos ao símbolo, como podemos ver no exemplo abaixo.
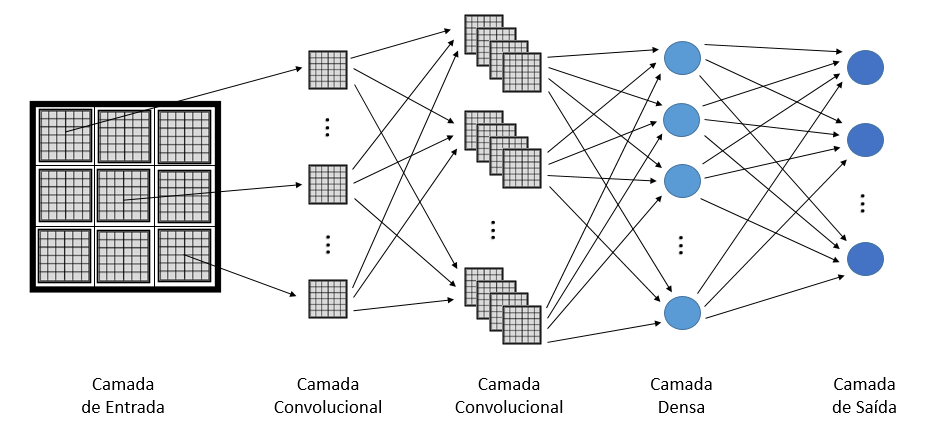
Na primeira camada convolucional, temos 2 conjuntos de 60 feature maps seguidos de um processo de max pooling; já a segunda camada convolucional é composta por 2 conjuntos de 30 feature maps seguidos também de um processo de max pooling. Logo após, ocorre o flattening dos feature maps para ser processado por duas redes neurais densas de 500 e 30 nós respectivamente.
Levnado em consideração o vetor gerado pelo flattening e os pesos sinápticos, o modelo pode então fazer sua previsão.
Alguns parâmetros precisam ser definidos para nosso modelo:
-
Batch: Número de imagens que vão passar pelo modelo de uma vez; no nosso caso, cada batch continha 32 imagens.
-
Epoch: Número de vezes que o modelo irá treinar em cima de todo o dataset; para nosso modelo, escolhemos o valor de 50 épocas.
-
Steps per epoch: Número de batches que irão rodar no modelo antes que se verifique a performance deste; definimos o valor de 1500 steps.
Para evitar overfitting, uma vez que o número de épocas foi arbitrário, usamos o API do TensorFlow para python, chamado Keras. Nele, achamos um conjunto de funções denominado Callback[14], permitindo fazer procedimentos em qualquer ponto do treino.
A funçao EarlyStopping, presente no conjunto Callback, interrompe o treino do modelo antes que haja um overfitting. Ela leva em consideração o valor a ser monitorado (função de perda), a variação no valor e o número de épocas sem melhora no modelo. Como resultado do nosso treino, nosso modelo foi interrompido após 11 épocas.
Feito o treino do modelo, podemos agora avaliar a precisão média para cada classe, dentre outras métricas.
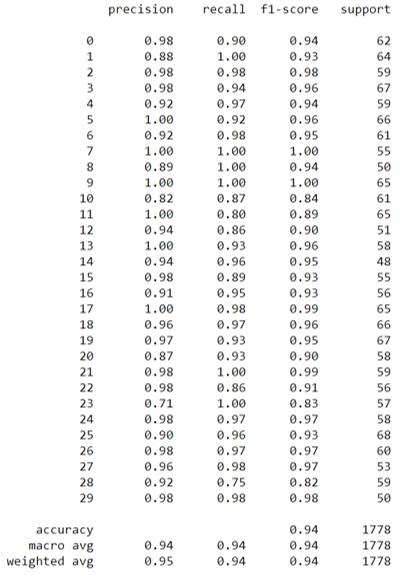
Resultados
Com nosso modelo devidamente treinado e avaliado, podemos agora fazer previsões a partir de uma web-cam, utilizando o módulo cv2 da biblioteca OpenCV para se usar em python. O programa lê a filmagem da web-cam como se fossem diversas fotos em sequência, prevendo a classe da imagem e disponibilizando a probabilidade de acerto da mesma.

Algumas classes apresentaram dificuldade na hora de prever corretamente o resultado devido à perda de qualidade no processo de tratamento das imagens; abaixo encontramos alguns casos em que o modelo não conseguiu reconhecer a classe.

Como mencionado anteriormente, nosso modelo interrompeu o treino em 11 épocas; plotando o gráfico da ácuracia, temos a linha azul para o conjunto de treino e a linha laranja para o conjunto de teste. A partir desse ponto, a acurácia começou a cair significativamente, forçando o comando Callback.

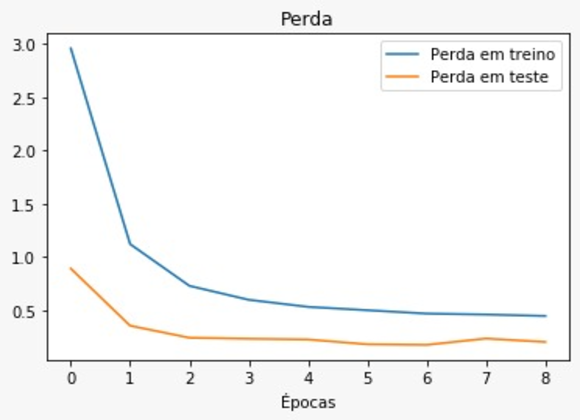
Agora avaliando a função de perda do modelo, podemos ver que na quantidade de épocas ótima, temos o menor valor para a função de perda; a partir desse ponto, a função voltava a crescer.
Conclusão e Pontos a Melhorar
Neste trabalho, abordamos o assunto de reconhecimento de caracteres matemáticos através de modelos de Machine Learning, mais concretamente utilizando-se da técnica de redes neurais convolucionais. Conseguimos visualizar como esse processo funciona por trás das linhas de código e como o modelo toma suas decisões, além de vislumbrar as diversas aplicações deste método para problemas distintos.
Mesmo conseguindo cumprir com o objetivo do problema, ainda restam pontos de melhoria no projeto, que podem ficar de inspiração para quem queira se aventurar. Nessa seção iremos elucidar alguns deles.
Uma primeira melhoria seria implementar uma caixa de contorno, como aquelas vistas em modelos de carros autônomos ou até mais recente, em modelos de reconhecimento do uso de máscara. Outra melhoria relacionada com esse ponto seria o reconhecimento do posicionamento do caractere, como por exemplo uma expressão dentro de raiz quadrada, algum índice subscrito ou de potência.
Com relação ao dimensionamento das imagens, tentamos rodar o modelo com imagens de dimensão maior que os 28x28 pixels escolhidos, porém isso afetou muito nosso resultado; um aumento na dimensão cria muito ruído, que acaba afetando a acurácia do modelo. Outro ponto seria melhorar o tratamento das imagens; melhorando a sensibilidade do filtro, o modelo poderia dar mais destaque ao número em si e relevar mais os ruídos. Uma melhora no tratamento das imagens pode contribuir com o problema encontrado no aumento da dimensão das imagens.
Por fim, a respeito do modelo, percebemos dois pontos passíveis de melhoria. Uma rede convolucional mais complexa e com mais camadas poderia solucionar o problema de ruído que enfrentamos, dando mais destaque ao número e relevando sombras e ruídos. Outro ponto do modelo que também poderia ser otimizado é o número de parâmetros, que também deixaria o modelo mais assertivo e confiável. O contraponto que isso gera é a relação Complexidade x Poder Computacional. É necessário um estudo mais a fundo de como o aumento na complexidade do modelo poderia afetar o consumo de poder computacional, gerando maiores gastos.
Referências
[1] MACHINE-Learning-Projeto-UFPR-Reconhecimento-de-algarismos. GitHub. Disponível em: https://github.com/Egmara/Machine-Learning-Projeto-UFPR-Reconhecimento-de-algarismos. Acesso em 12 de abril de 2020
[2] ESTUDO matemático do reconhecimento de caracteres. GitHub. Disponível em: https://abelsiqueira.github.io/assets/alunos/2017/carlos-ronchi.pdf#page=40&zoom=100,112,66. Acesso em 12 de abril de 2020
[3] FILE: Typical cnn.png. Wikipedia. Disponível em: https://en.wikipedia.org/wiki/File:Typical_cnn.png. Acesso em 20 de maio de 2020.
{kind=link}
[4] CONVOLUTIONAL Neural Networks (CNN): Step 1- Convolution Operation. Super Data Science. Disponível em: https://www.superdatascience.com/blogs/convolutional-neural-networks-cnn-step-1-convolution-operation. Acesso em: 12 de maio de 2020.
[5] CAPÍTULO 43 – Camadas de Pooling em Redes Neurais Convolucionais. Deep Learning Book. Disponível em: http://deeplearningbook.com.br/camadas-de-pooling-em-redes-neurais-convolucionais/. Acesso em: 12 de maio de 2020.
[6] CONVOLUTIONAL Neural Networks (CNN): Step 2 - Max Pooling. Super Data Science. Disponível em: https://www.superdatascience.com/blogs/convolutional-neural-networks-cnn-step-2-max-pooling/. Acesso em: 12 de maio de 2020.
[7] CONVOLUTIONAL Neural Networks (CNN): Step 3 - Flattening. Super Data Science. Disponível em: https://www.superdatascience.com/blogs/convolutional-neural-networks-cnn-step-3-flattening. Acesso em: 12 de maio de 2020.
[8] CONVOLUTIONAL Neural Networks (CNN): Step 4 - Full Connection. Super Data Science. Disponível em: https://www.superdatascience.com/blogs/convolutional-neural-networks-cnn-step-4-full-connection. Acesso em: 12 de maio de 2020.
[9] EXAMPLE: Neural network. TEXample. Disponível em: http://www.texample.net/tikz/examples/neural-network/. Acesso em 20 de maio de 2020.
[10] HANDWRITTEN math symbols dataset. Kaggle. Disponível em: https://www.kaggle.com/xainano/handwrittenmathsymbols. Acesso em: 15 de abril de 2020.
[11] HASYV2: HandWritten Alphanumeric chars - Numbers, Letters, Mathematical & Scientific Symbols. Kaggle. Disponível em: https://www.kaggle.com/guru001/hasyv2#symbols.csv. Acesso em: 15 de abril de 2020.
[12] THE Chars74K dataset. EE Surrey. Disponível em: http://www.ee.surrey.ac.uk/CVSSP/demos/chars74k/. Acesso em: 15 de abril de 2020.
[13] IMGPROC. Image Processing. OpenCV. Disponível em: https://docs.opencv.org/2.4/modules/imgproc/doc/imgproc.html. Acesso em 20 de maio de 2020.
[14] CALLBACKS API. Keras. Disponível em: https://keras.io/api/callbacks/. Acesso em 20 de maio de 2020.